
广州pos机-10分钟揭秘被神化的个人征信报告的建模
美国的个人征信市场属于市场主导型,而中国的个人征信市场属于政府主导型。
美国个人征信体系有三大征信机构(Equifax、Experian和Trans Union)三足鼎立。
中国只有一家征信机构,即中国人乐刷刷卡机民银行,也称“央行”。

下面介绍一下美国和中国的征信信息及其应用。
一、美国信用评分及征信报告
Experian、Equifax和Trans Union各自采集原始征信数据,并同时输出两个标准化信用评分产品乐刷刷卡机——Vantage Score和FICO Score。
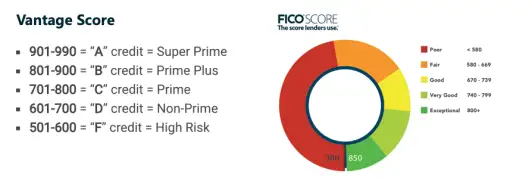
为什么会有两种评分呢?FICO Score是一家名为FICO的公司打造的。这家公司与征信三巨头不同,它本身并不掌握个人或企业的信用数据,只受托处理乐刷刷卡机征信巨头信用报告中的数据,通过模型给出个人信用评分,即FICO Score。该评分除了通过征信巨头售卖外,FICO自己也售卖。在这一产品层面上,三巨头与FICO是合作关系。

但另一方面,三巨头联合开发了乐刷刷卡机Vantage Score来对抗FICO Score,形成了两大评分产品瓜分市场的竞争关系。

除了信用评分,三巨头的另一种产品输出形态是征信报告。三家报告均采用了统一标准数据报告格式和采集格式,报告内容乐刷刷卡机基本相同。
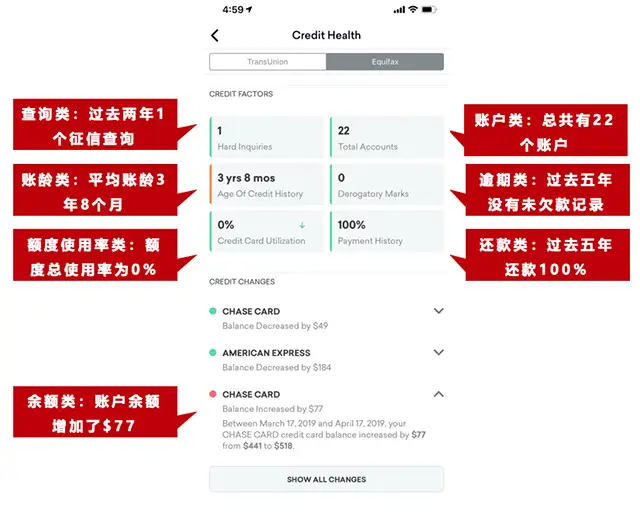
图1 以Equifax的报告为例,某信用卡持卡人个人征信报告截图
乐刷刷卡机评分的服务,支持查看Equifax和TransUnion的信用评分和信用报告。)
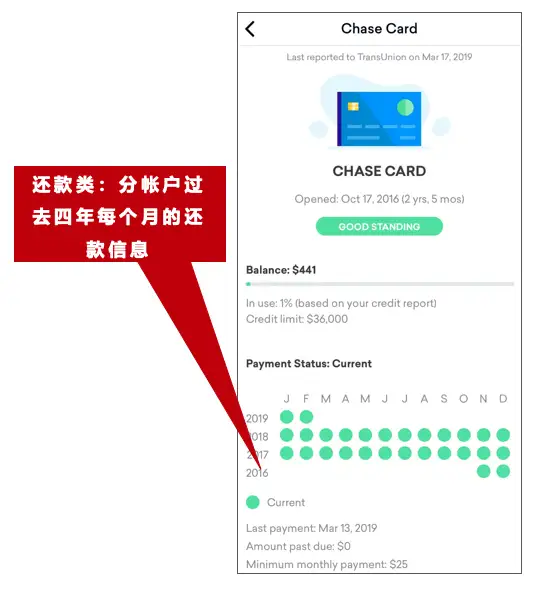
图2 以Equifax的报告为例,某信用卡持卡人个人征信报告截图
二、中国信用评分及征信报告
中国的征信信息相比美国就不一样乐刷刷卡机了。
首先,中美的征信报告内容有些差异。
个人基本信息:年龄、性别、学历、配偶信乐刷刷卡机息等;
贷款信息:贷款类型、贷款金额、个数和周期等;
信用卡信息:信用卡额度、还款信息、逾期信息等;
逾期信息:贷款逾期信息、信用卡逾期信息、连续逾期、累计逾期等;
查询信息:查询机构个数、查询机构类型以及查乐刷刷卡机询原因等;
公积金信息:缴纳金额、缴纳比例等;
其他信息:拥有征信记录时长、负债信息等。
乐刷刷卡机的话,你会看到你的征信报告可能是厚厚的一沓。


但是!各个金融机构可以依据征信信息提炼各自的评分!
如何提炼出乐刷刷卡机像FICO Score和Vantage Score那类评分呢?

第一阶段
当金融机构向人行征信报告平台提交查询申请,得到了某个人的征信报告,然后进行肉眼审查,来判断是否应该通过这个人的贷款申请或信用卡申请乐刷刷卡机。

该阶段也称为原始人时期。
第二阶段
金融机构查询了某个人的征信报告,将报告自动输入进自身系统,然后通过从征信报告中萃取出来的、事先制定好的策略和规则,电脑自动判断是否应该通过这个人的贷款申请或信用卡申请乐刷刷卡机。这是原始到现代的过渡期,即智人时期。

第三阶段
在这个阶段,可以利用个人征信报告“数字解读”这个功能来做风控,它是利用了跨行跨业务样本开发的通用评分,这也决定了它并不完全适用于各家金融机构的自身业务特点乐刷刷卡机
第四阶段
这个阶段就比较高级了,金融机构将人行征信报告平台返回的报告输入进自身系统,系统将报文解析后,自动算出这个人的风险评分,然后电脑判断乐刷刷卡机这个分数是否达到了审批的“及格线”,即阈值。
这个专有风险评分是在征信报告报文解析的基础上,经过特征工程加工和变量衍生后,训练模型,然后调整模型到风险区分度最高、可解释性最强、最稳定的状态,带有金融机构乐刷刷卡机自身客群特点的评分。

若将征信信息应用于审批策略,报告里的每一项都需要提炼,电脑乐刷刷卡机每“看完”一个报告需要设定很多策略;模型是将征信报告凝炼精华后,总结为一个分数。两种应用方式对比如下:

图4 个人征信报告应用场景对比
征信报告模型评分大有用处,让征信报告的应用不再局限于授信环节,报告“乐刷刷卡机

图5 个人征乐刷刷卡机信报告衍生变量及其应用场景
但是另一方面,能直接从征信报告里挖掘的信息非常有限,因此衍生变量萃取是需要凝聚智慧与经验的过程。
下面这部分就要说如何做出“凝聚智慧与经验”的征信报告变量和模型了。
乐刷刷卡机信信息变量绝不能机械式地生成,更加重要的是,如何持续产出创新性的衍生变量思路,让模型分数更加稳定耐用。

图6 征信报告衍生变量加工乐刷刷卡机的痛点及解决方案
作为一家专业的金融科技服务商,通过处理和应用人行征信数据,可帮助机构判断贷款申请客户风险程度,并针对性地提供“秘籍”,也就是如何利用原始信息生产出有用的变量。
第一招:借力打力
征信信息对乐刷刷卡机于金融机构的好处之一,就是能看到申请人在其他家的借贷历史,那么如何借助这样的历史,把坏人拒之门外呢?
融慧秘籍“借力打力”的含义是,通过模拟申请人在其他金融机构的申请通过率,推算这个申请人的信用风险,节乐刷刷卡机省了自己测试这个人的力气。
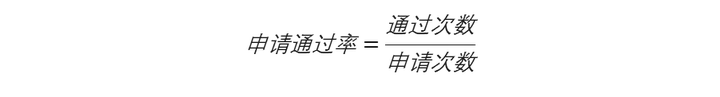
解:
已知1:提交第一次信用卡或贷款的申请的那一刻起,你就拥有了征信报告,也就是说征信报告会包括每个人几乎所有的征信历史。
已知2乐刷刷卡机:征信报告中,有一类信息是信用卡申请查询或贷款申请查询次数,顾名思义,就是其他金融机构查询这个人征信信息的次数。而且重要的是,还要设置时间条件在这个变量上,比如一个月内或者半年内。
(这里要特别注意的是乐刷刷卡机,“查询次数”虽然不代表“申请次数”,但为模拟“申请通过率”,借助“查询次数”来接近“申请次数”这个概念。)
已知3:同理,借力打力,用“贷记卡账户数”、“贷款笔数”等各类账户之和,来近似申请“通过次数乐刷刷卡机”。同样地,设置时间条件比如一个月内或者半年内。
那么,衍生这个变量的大致思路如下
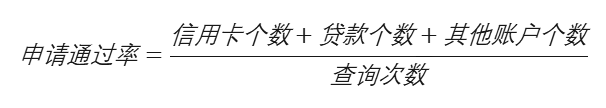
(这个公式仅用于举例说明衍生变量加工思路,不代表真实变量加工过程。)
第二招:八面玲珑
不是所有带有逾期历史的人都是坏人,忘乐刷刷卡机记还款后,立即补还的情况还是存在的。为了避免以偏概全,这些被“误杀”的好人,应该被捞回。那么这些如何从征信报告中识别出来?
举个例子,如下图所示,某个人征信报告,其中包括了2015年09月-2017年0乐刷刷卡机8月的还款记录。“*”表示本月没有还款历史,“N”表示还款正常,“1”表示逾期1~30天。可以看到这个人在两年内,状态正常——逾期——状态正常的次数有3次,且都是30天内逾期,可以初步判断这个人属于“乐刷刷卡机有价值的好人”,也可称之为“灰客户”。
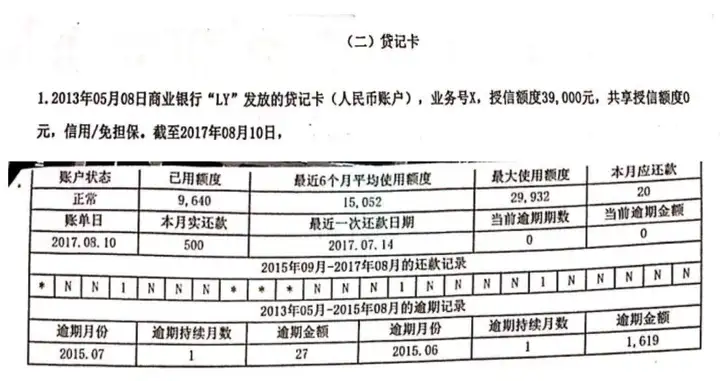
图7 征信报告的贷记卡信息节选
这个例子告诉大家如何避免对所有逾期客户一概而论,而是对客户价值进行细分,各方面都照顾到,因此这招叫做“八面玲珑”。
这里只是举出了人行乐刷刷卡机征信报告一代的例子,而在人行征信报告二代中,还款记录延长到了5年,而且增加了逾期金额等信息。通过分析客户在过去5年内的逾期行为记录,将不同逾期表现的客户进行细分,并加工为变量的难度将会提高。
乐刷刷卡机籍还有很多,成果也有一些。

我们的合作流程如下:
1.创造模型中的X:利用上述“秘乐刷刷卡机籍”们,团队帮助客户基于征信报告加工出来1万多个变量。
2.定义模型中的Y:同时,充分了解机构客户的业务类型、产品、客群特点、客户逾期表现及滚动率,定义出模型好坏标签。(若机构已有基于征信报告的策略,建乐刷刷卡机议用已被征信策略筛选过的样本。)
3.开始建模:用Y标签进行建模,因为征信信息与信贷业务强相关,逻辑性较强,一般用逻辑回归方法(LR)进行征信模型建模。
4.模型验证:模型搭建完毕,下面就是检验变量区分度乐刷刷卡机、可解释性和稳定性的时刻了。
1) 区分度验证:
我们把模型分数按从大到小排序,然后,温柔又快速地,把他们平均切分为20组,再把逾期信息和分数一一对应好,就可以看到每组分数抓到的坏人和好人个数占比,这里有乐刷刷卡机个指标可以描述模型抓住坏人的准确程度——KS。同类的区分度指标还有AUC、Gini等。
对多家金融机构进行专有征信评分建模,成功的模型效果可参考下图:当机构拒绝25%的申请人的情况下,捕获其中51% 的乐刷刷卡机坏人。
图8 征信报告专有模型效果案例
金融机构需要在申请通过率和业务收益之间做一个平衡,来测算最适合自身业务要求的坏人捕获率及申请通过率。
2) 检验变量可解释性:如下是征信报告中的“(二)逾期及违约信息乐刷刷卡机概要”和“(三)授信及负债信息概要”。
可以看出,例子中的这个人曾有逾期1个月,金额1619元的历史,还有两笔将近71万元的贷款未结清,而其他家总共授予约62万元的额度,已用额度约22万元等诸多信贷类信乐刷刷卡机息,反映出了这个人负债在身,有轻微逾期历史的特点。此类信息为判断客户的信用风险和还款能力帮了大忙,因此基于征信报告做出来的模型,可解释性相比其他数据来说是相对较强的。
图9 征信报告的逾期及违约信息概要乐刷刷卡机案例
3) 稳定性验证:
乐刷刷卡机,实验室中的好模型,实践中的差模型,我们见得太多了。
因此,在建造模型的过程中,不仅追求对数据的极致化挖掘,而且要将模型搭建得非常稳健,确保模型上线后具有足够的风险区分度和时效性。(建模是个技术活,更是乐刷刷卡机个艺术活和良心活。)
经过了检查PSI(最常见的模型稳定度评估指标),或者在跨样本及跨时间窗口验证集上检查模型Gini和KS等步骤后,如果得到了一个表现稳定的模型,那么专有征信评分建模就基本可以完成了。乐刷刷卡机
商务广告咨询请添加微信:1292496908

